
Wachsende Datenmengen und neue Internet-Anwendungen stellen neue Anforderungen an die Speicherung und Auswertung großer unstrukturierter Daten. Wir werden hier einige NOSQL-Produkte und die dahinter steckenden Verfahren vorstellen. Neben einem Vergleich mit den bestehenden klassischen Datenbanken werden wir auch zeigen, wo sich diese heute schon ergänzen.
Es ist paradox: Daten zu speichern wird zwar immer billiger, trotzdem geben Unternehmen immer mehr Geld für Datenspeicherung und -verarbeitung aus, da die Menge sich alle zwei Jahre verdoppelt und Daten zu einem immer wichtigeren Informations- und Produktionsfaktor werden. Nach der aktuellen Studie „Digital Universe“ von IDC werden dieses Jahr 1,8 Zettabyte, das sind 1,8 Billionen Gigabyte, digitale Daten weltweit erzeugt, die schon gar nicht mehr alle gespeichert oder verarbeitet werden können. Diese großen Datenmengen, die mit Hilfe von Standard-Datenbanken und -Tools nicht oder nur unzureichend verarbeitet werden können, werden als Big Data bezeichnet.
Eine neue Ära beginnt – Aufstand imSQL-Land
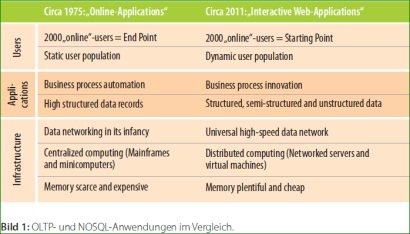
Internet-Firmen wie Google oder Amazon haben schon länger sehr große Datenmengen zu bewegen. Deswegen haben sie neue Verfahren erforscht und eingesetzt, wie sie effizient und kostenbewusst mit diesem enormen Wachstum bei gleich guter Performance umgehen können. Statt hochspezialisierter Hard- und Software verwenden sie einfache, standardisierte und nach ihren Anforderungen entwickelte intelbasierte Linux-Rechner mit eigener Software vom Betriebssystem bis hin zum Dateisystem. Als ein Verfahren, um große Datenmengen zu durchsuchen, hat Google den parallelen Map-Reduce-Algorithmus veröffentlicht und in seinem spaltenorientiertem BigTable implementiert, die auf dem Google File System basiert. Auch andere Internet-Firmen wie Facebook (Cassandra) und Amazon (Dynamo) haben eigene Datenbanken entwickelt, um ihre immer stärker vernetzten und wenig strukturierten Daten verteilt und flexibel verarbeiten zu können.
Anders als in traditionellen OLTP-Anwendungen mit tausend parallelen Benutzern und Daten im Gigabyte-Bereich haben diese Firmen Millionen parallele Benutzer und Tera- bis Petabyte an Daten bei sehr hohen Wachstumsraten. Waren die typischen OLTP-Anwendungen meist nur an den Arbeitstagen und zu den üblichen Arbeitszeiten im Betrieb, sind Internetanwendungen rund um die Uhr im Einsatz. Daten müssen heute in Echtzeit ausgewertet und Anwendungen ohne Ausfälle aktualisiert werden. Statt die zentralen großen Server immer mehr aufzurüsten, werden Daten auf vielen kleinen und regional verteilten Servern gespeichert. Ein wesentliches Funktions- und Erfolgsmerkmal des Internets ist seine hohe Ausfalltoleranz und Skalierbarkeit.
Statt Transaktionssicherheit reicht für interaktive Webanwendungen eine schwache Konsistenz, wenn Verfügbarkeit und Skalierung gegeben sind. Diese wichtige Eigenschaft wird als BASE-Prinzip (Basically Available, Soft-State und Eventual Consistency) bezeichnet und ist im CAP-Theorem zusammengefasst. Dieses Theorem besagt, dass immer nur zwei der nachfolgend angeführten drei Eigenschaften gleichzeitig zu erreichen sind:
- Konsistenz: Eine Operation wird systemweit immer vollständig oder gar nicht durchgeführt.
- Verfügbarkeit: Alle Knoten enthalten alle Daten lokal als Replikate.
- Partitionstoleranz: Auch beim Ausfall einer Partition bleibt das System verfügbar.
Die zentralistische Architektur der relationalen Datenbanken kommt aus den 70ern, als das Internet, wie wir es heute kennen, noch in weiter Ferne war, versuchte möglichst effizient mit den knappen und dadurch teuren Rechnerressourcen umzugehen. Michael Stonebraker, dessen Ideen zu Datenbanken seit Jahrzehnten in viele Datenbankprodukte eingeflossen sind, hat bereits „The End of an Architectural Era“ ausgerufen. Das bedeutet aber nicht, dass die bestehenden und sehr ausgereiften relationalen Datenbanken verschwinden werden.
Es wächst zusammen, was zusammengehört
Den Graben zwischen Objekten und Relationen hat man durch Persistenzframeworks oder objekt-relationale Erweiterungen überwunden und mit Clustern wurden die Datenbanken ausfallsicherer gemacht. Mussten Datenbanken angepasst, gewartet oder auf größere Hardware migriert werden, so war das nicht ohne Ausfälle möglich. Für Spezialanforderungen gab es auch bisher Datenbanknischen für XML, hierarchische oder dokumentenorientierte Datenbanken. Die Historie der Datenverwaltungssysteme zeigt, dass es immer wieder unterschiedliche technische Ansätze gab und geben wird. Wobei viele über ein Nischendasein nicht herausgekommen sind.
Durch das Oligopol der vier großen Hersteller ORACLE, IBM, SAP undMicrosoft bleibt wenig Platz für echte Datenbankinnovationen. Heutige Anwendungen müssen flexibel im Netz oder auf mobilen Geräten laufen. Deswegen sind eine schnelle Anpassbarkeit und eine lineare Skalierbarkeit nötig.

Die unter NOSQL (was für Not only SQL steht) zusammengefassten Systeme verwenden unterschiedliche Konzepte. Um eine schnellere Verarbeitung oder effizientere Speicherung ohne zusätzlichen Transformations- und Denormalisierungsaufwand zu erreichen, verwenden sie recht einfache Speicherformate. Angefangen von der großen Gruppe der schlüsselwertorientieren Datenbanken wie Simple DB, Azure Table Storage, Dynamo, BigTable oder Membase. Gefolgt von davon abgeleiteten dokumentenorientieren Datenbanken wie Riak, MongoDB oder CouchDB. Als Spezialfall gibt es noch spaltenorientierte Datenbanken wie Hbase, Cassandra oder Hypertable und graphorientierte DatenbankenwieNeo4j, GraphDB oder Sones. Die meisten der NOSQL-Datenbanken bieten für die Verarbeitung und Abfrage der Datenbank eigene proprietäre APIs und spezialisierte Abfragesprachen an.
Aus dem Web für das Web
So verwendet CouchDB das REST-basierte http-Protokoll. Andere Produkte bieten zumindest als Ergänzung eine JDBC-Datenbankschnittstelle an, was die Integration oder Migration von bestehenden Systemen erleichtert. Es hat sich gezeigt, dass zum Verarbeiten semistrukturierter Daten eine andere Abfragesprache als SQL benötigt wird, da diese Daten nicht als Menge, sondern hierarchisch aufgebaut sind. Durch das direkte Arbeiten mit Webressourcen entfällt der zusätzliche und fehleranfällige Abbildungsaufwand.
Wichtig bei diesen Produkten ist, dass es sich nicht um Forschungsprototypen handelt, sondern dass diese bereits seit Jahren in der Praxis erprobt sind und zum größten Teil als Open-Source weiterentwickelt werden. Zu den meisten Produkten gibt es bereits einige kommerzielle Partner, die sich um einen professionellen Support und die weitere Verbreitung der Produkte kümmern.
So haben sich CouchDB- und Membase-Entwickler zur Firma Couchbase zusammengeschlossen. Hinter anderen Produkten, wie der Apache Hadoop-Familie, steht eine breite Unterstützung von Firmen unterschiedlichster Art und Motivation wie IBM, Yahoo und Cloudera. Bei Apache Hadoop handelt es sich um einige von den Google-Ideen inspirierte Unterprojekte wie der ursprünglich von Facebook stammenden Data-Warehouse-Infrastructure Hive. Die Basis von Hadoop ist sein Hadoop Distributed File System und MapReduce-Framework. Dieses wird ergänzt umProdukte wie Chukwa zur Echtzeitüberwachung, ZooKeeper zur verteilten Konfiguration, Pig zur Analyse großer Datenmengen mit der HBase-Datenbank, die eine freie Implementierung von Google BigTable ist. Die von Facebook verwendete Hadoop-Datenbank gehört mit mehreren Petabytes zu den größten der Welt, wobei täglich mehrere Terabytes mit dem Hadoop-MapReduce-Framework durchsucht werden.
Ebenso setzt das CERN die CouchDB zum schnellen Speichern und Verarbeiten der Daten seines neuen Teilchenbeschleunigers ein. So kehren Webdatenbanken, wie CouchDB, an den Geburtsort des Webs zurück. Ein weiteres prominentes Beispiel ist die durch Farm-Ville und CityVille bekannte Spielefirma Zynga, die CouchDB für mehrere Millionen Online-Spieler täglich verwendet. Ein anderes Beispiel für einen Offline-Online-Speicher ist der Cloud-Dienst UbuntuONE, der es allen Ubuntu-Benutzern erlaubt, ihre in CouchDB gespeicherten persönlichen Daten ins Netz zu replizieren und so von allen möglichen Endgeräten zugreifbar zu halten.
Dass SQL- und MapReduce-Verarbeitung kein Widerspruch sein muss, zeigen das auf DB2 und Hadoop basierende IBM-Produkt InfoSphere BigInsights oder das EMC-Produkt Greenplum, das auf PostgreSQL beruht und dieses um einen Map-Reduce-Algorithmus ergänzt. Ebenso bietet Microsoft für seine Cloud-Umgebung Azure, sowohl einen Spaltenspeicher als eine Umsetzung des MapReduce-Algorithmus an.

Bleibt alles anders und offen
Die bereits existierenden NOSQL-Systeme sind sehr unterschiedlich. Dadurch, dass diese von Anfang als Open-Source verfügbar waren, konnten sie schnell an die noch fehlenden Anforderungen hinsichtlich Skalierbarkeit, Betrieb, Integration und Sicherheit angepasst werden. Inzwischen sind um diese OpenSource-NOSQL-Systeme professionelle Firmen entstanden, die deren Entwicklung nachhaltig voranbringen. Teilweise ist es schon, wie das Beispiel CouchDB und Membase zeigt, zu einer Konsolidierung gekommen, wobei sicher die NOSQL-Ansätze von den etablierten Anbietern wie IBM oder ORACLE in ihre Produkte übernommen werden oder einige professionelle NOSQL-Firmen direkt aufgekauft werden. Dadurch, dass die meisten Basisprodukte von Anfang an als OpenSource verfügbar sind und deren technische Grundlagen entweder schon länger bekannt sind oder durch neuere Forschungsarbeiten bestätigt wurden, ist hier eine langfristige Investitionssicherheit gegeben. Bisher haben sich Forschung, OpenSource und ClosedSource in diesem Bereich sehr gut ergänzt.
Die Zukunft gerade in diesemBereich bleibt spannend, da mit Cloud,Web 2.0 und mobilen Geräten ganz neue Anforderungen an neue Anwendungen und deren Daten gestellt werden.
Fazit
In der ersten Dekade des neuen Jahrtausends ist das Internet mobil und sozial-interaktiv geworden. Neben dem sich daraus ergebenden enormen Datenwachstum stellen sich ganz neue Herausforderungen an die effiziente Datenverarbeitung und dynamisch skalierbaren Anwendungen. Hier können die untereinander recht unterschiedlichen NOSQL-Datenbanken punkten und die bestehenden relationalen Datenbanksysteme gut ergänzen.
Frank Pientka, Senior Consultant, MATERNA GmbH
Diesen Artikel lesen Sie auch in der it management , Ausgabe 12-2011.




