
Kodifiziertes, das heißt in elektronischer Form hinterlegtes Wissen im Unter-nehmen ist nur dann wertvoll, wenn es kontextbezogen aktuell und schnell zur Verfügung steht. Das große Risiko bei der Einführung von Wissensmanage-mentsystemen besteht darin mit hohem Aufwand Wissensbestände aufzubau-en, die diesen Kontextbezug nicht besitzen und damit den Anwendern keinen Nutzen bieten. Dieses Wissen ist wertlos, weil nicht verwertbar.
Durch umfangreiche Retrieval- bzw. Suchsysteme mit einer intuitiv zu bedie-nenden Suchoberfläche, soll das in den vorhandenen, unternehmensspezifi-schen Datenbanken, Applikationen und Internetpräsenzen implizit vorhandene organisatorische Wissen über eine intelligente, das heißt strukturierte, kontext-abhängige und kognitive, mit Handlungsmustern versehene Datenbanklösung explizit verfügbar gemacht werden. Hierbei können eine ganze Anzahl ver-schiedener interaktiver und automatischer Retrieval- bzw. Such- und Naviga-tionsmechanismen Anwendung finden. Entsprechend lassen sich unterschei-den:
-
Retrievalfunktionalitäten, zum Beispiel:
– Datenbankabfragen,
– Volltextsuche
– Bilderkennung
– Spracherkennung
– Datamining / OLAP / BI (Business Intelligence) -
Browserfunktionalitäten, zum Beispiel:
– Softwareagenten
– assoziatives Navigieren
– Semantische Suche.
Während es sich bei Retrievalsystemen um die Eingabe von Suchbegriffen han-delt, wird das Navigieren durch Topic Maps oder Semantische Netze als Brow-sing bezeichnet. Bei Letzterem handelt es sich um das manuelle oder automa-tische Navigieren in strukturierten Datenbeständen. Die bereits beschriebenen eingesetzten Dokumentemanagementsysteme (DMS) ermöglichen mit ihren Dokumentenverzeichnissen, Versionsverwaltung, Dokumentenhistorie, Nutzer-verwaltung, Zugriffskontrolle, Verteilerhistorie, Freigabehistorie mit den dahin-ter stehenden Konfigurationsmanagement, das heißt Verwaltung, Verteilung und Pflege der Dokumente, ihren Wissensbeitrag um den berechtigten Benut-zern die relevanten elektronischen Dokumente zur Bearbeitung zur Verfügung zu stellen. Diese sind nach unterschiedlichen Informationsarten zu differenzie-ren, beispielsweise nach Kundendokumenten, Präsentationen, Fotos, Veröffent-lichungen, Druckbeschreibungen, Regelwerken, Normen und Ähnlichen. Diese Strukturierung der Informationsarten lässt sich noch weiter nach Dokumenten-arten, Dokumentengattung, Dokumententyp, Dokumentenklassen verfeinern, um so die Klassifizierung für das automatische Indizieren zu ermöglichen. Hier-bei leisten auch konventionelle Aktenpläne als übergreifende Firmenverzeich-nisse eine gute Strukturierungsvorgabe.
Vereinfachte Dateisuche
Der Einsatz von Dokumenten Retrieval Systemen, die unstrukturierte Daten von Textverarbeitungen oder Tabellenkalkulationen verwalten, helfen dem An-wender nach Dateien zu suchen, die einen bestimmten Schlüsselbegriff enthal-ten, von einem bestimmten Mitarbeiter erstellt wurden oder in einem vorgege-benen Zeitraum hinterlegt wurden. Durch Einsatz aktiver Informationsfilter wer-den diese Datenbestände nach bestimmten Formationen selbstständig durch-sucht und hierbei spezifizierte bzw. bestimmte Ereignisse oder Themenkreise lokalisiert, über die der Anwender kontinuierlich informiert werden möchte. Mit Hilfe von nachfolgend noch näher erläuterten Softwareagenten durchsuchen die Filterprogramme regelmäßig die Datenbestände nach diesen Objekten und weisen auf die Ergebnisse hin. Über Grafik- oder Webtools können mehrdimen-sionale Darstellungen aller Unternehmensdatenaspekte beispielsweise kunden-, produkt-, zeit-, perioden-, gebiets- oder kontenbezogen in beliebiger Kombi-nation grafisch abgebildet werden. Anschließend können die Ergebnisse oder Berichte per EMail verschickt oder im Internet/Intranet zur Verfügung gestellt werden.
Um eine bedarfsgerechte Informations- und Wissensbereitstellung zu unter-stützen, können individuelle Benutzerprofile erstellt werden, die personalisierte Regelungen beinhalten. Hierbei wird festgelegt, welcher Mitarbeiter welche In-formationen bei welcher Tätigkeit erhält, auf welche Ressourcen er zurückgrei-fen kann und welche IT-Infrastruktur ihm zur Verfügung steht.
Mit dem Benutzerprofil lässt sich auch die Struktur des elektronischen Berichts-wesens festlegen. In Abhängigkeit von Hierarchie und Position werden dem Be-nutzer die Berichte und Reports zugeordnet, in die er Einblick bekommt. Bei-spielsweise TOP-Managementberichte, Finanzberichte, Kundenberichte, Kom-mentare der Projektberichte usw. Um tatsächlich kontextspezifisches und hand-lungsrelevantes Wissen zu erhalten, müssen jedoch vorher Strukturierungen der im Portal vorhandenen Datenquellen und unterschiedlichen digitalen Objek-te, zum Beispiel über:
-
Standardisierte Ordnungs- bzw. Begriffsysteme
-
Metadatenzuordnung zur Objektverwaltung (nicht thematisiert)
-
Metadatenordnung zum Objektinhalt (thematisiert)
-
Klassifikationen und Gliederungen zum Beispiel in Form von Merkmals-leisten
-
interaktive Fachwörterbücher
-
Inhaltsverzeichnisse und Verzeichnisdienste
-
Themenlisten mit Zuordnung von Website und Datenbank
in eine intelligente Prozesslogik eingebunden werden. Die Prozesslogik selber wird hier durch das nachfolgend erläuterte Prozessvisualisierungsmodell mit der detaillierten Beschreibung der Führungs-, Aufbau- und Ablauforganisation unter der Zuordnung aller Daten- und Informationsquellen vorgegeben.
.")
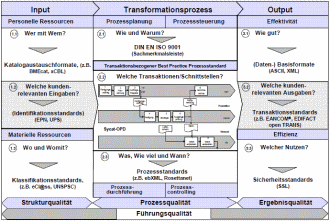
Bild 1: Systematische Beantwortung der Prozessanalysefragen mit SYPAM (Systematischen Prozessanalysemethode)
In der in Bild 1 innerhalb der Systematischen Prozessanalysemodellstruktur (SYPAM) gezeigten sycat Organisationsprozessdarstellung (OPD) können für die definierten Prozesse beliebig variierbare, aber definierte Beziehungen her-gestellt werden. Hierbei wird in der sachlich-logischen und zeitlichen Reihenfol-ge exakt festgelegt, wodurch ein Prozess ausgelöst wird, welche Transaktionen in welcher Reihenfolge auszuführen sind, welche Objekte, Daten und Dokumen-te erzeugt, bearbeitet, dokumentiert und weitergeleitet werden, wer an wel-cher Stelle für welche Transaktionen und Aufgabenerledigung verantwortlich ist oder welche Schwachstellen und Defizite im Prozessablauf existieren. Über diese Weise lässt sich die Kommunikation durch Input / Output Beschreibung und die Aktionsbeschreibung (Transaktion, Operation) zwischen den einzelnen Objekten darstellen. Diese Objekte sind beispielsweise der Prozess selbst, aber auch die Bereiche, Akteure, Funktionen, Arbeitsschritte und vieles mehr, wobei die dargestellten Beziehungen beliebig untereinander kombiniert werden können.Die von Prof. Binner entwickelte Systematische Prozessanalysenmetho-de SYPAM verwendet die sycat Prozessdarstellung gleichzeitig als Wissensme-tastrukturvorgabe und ermöglicht so den Anwendern, strukturiert alle notwendi-gen Prozessparameter innerhalb des Transformationsprozesses bei der Pro-dukt- oder Dienstleistungserstellung von der Prozesseingabe über die Prozess-durchführung bis zur Prozessausgabe zu erfassen. Hierbei wird gleichzeitig ei-ne Stärken-/Schwächenanalyse sowie Chancen-/Risikobetrachtung durchge-führt. Bezugspunkt ist hierbei immer der mit sycat Process Designer abgebil-dete Geschäftsprozess in der charakteristischen Organisationsprozessdarstel-lung (OPD), heute weltweit als Swimlane bezeichnet.
Eindeutiger Datenaustausch
Entsprechend dieser Unterscheidung nach Input, Transformationsprozess und Output werden bei SYPAM systematisch Antworten zu den in Bild 1 genannten Fragen gegeben. Jede Frage bezieht sich auf ein Analysesegment.
Die zu beachtenden Standardvorgaben als Grundlage für einen eindeutigen Datenaustausch oder zur Klassifizierung von Wissen sind ebenfalls genannt. Auf diese Weise werden beispielsweise kundenbezogen folgende Wissens-grundfragen beantwortet:
-
Welches Wissen ist in den Geschäftsprozessen vorhanden?
– Wer sind die Wissensträger? -
Welches Wissen ist verfügbar? (Wissensbestand)
– In welcher Form? -
An welcher Stelle sind die Wissenslücken?
– In welcher Ausprägung? -
An welcher Stelle im Prozess besteht welcher zusätzliche Wissensbedarf?
-
Welche Maßnahmen (Wissensaktivitäten) sind zu ergreifen, um den ver-fügbaren Wissensbestand zielgesichert zu gestalten und kontextbezogen bereitzustellen?
Content Ablagestrukturen
Die wichtigste Voraussetzung für die zuletzt genannte Wissensmanagement-grundfrage, das heißt Wissen mit den dahinter stehenden Informationen gezielt zur Verfügung zu stellen, ist eine einheitliche Ablagestruktur mit definierten Re-geln zum Selektieren, Kombinieren, Sammeln, Bewerten, Ordnen oder Aufbe-reiten von Wissen. In dieser Ablagestruktur müssen die Inhalte über Metada-ten wie zum Beispiel Inhaltsangaben, Zielgruppen oder Beziehungen zu ande-ren Dokumenten für die Vernetzung strukturierter Abfragen, Interaktionen und Kollaborationen zur Verfügung stehen.
Diese Metadaten ermöglichen die integrierte Suche über unterschiedliche Zu-gangspfade wie beispielsweise Volltextsuche, assoziatives Navigieren, interak-tive Webservices, Taxonomien mit Thesauri und Klassifikation, Mustererken-nungen, aber auch direkter Zugriff zu den visualisierten Prozessketten inner-halb des Produktlebenszyklus. Über diese Verknüpfung des sycat Prozessmo-dells mit den Metabezugsdaten und -methoden wird das mit dem Kontext- und Strukturwissen eng verbundene Beziehungswissen abgebildet. Wie bereits er-läutert und in Bild 1 dargestellt, handelt es sich hierbei beispielsweise um so-ziale Beziehungen, räumliche Beziehungen oder Kommunikationsbeziehungen.
Die Offenlegung der Gruppierungs-, Raum-, Führungs-, Potenzial-, Organisati-ons-, Prozess-, Arbeits und Informationsbeziehungen innerhalb der sycat OPD ermöglicht durch die Bildung von semantischen Relationen bei der darauf auf-setzenden Zuordnung unterschiedlicher Prozessgestaltungssichten eine eindeu-tige Beschreibung der Anforderungen, Ziele, Maßnahmen, Umsetzungs- und Zielerfüllungsvorgaben.
Vorteile des semantischen Netzes
Der große Vorteil der semantischen Netze gegenüber der Volltextsuche ist das Finden von Dokumenten, die über- oder untergeordnete Begriffe enthalten und eine einfache Navigation, zum Beispiel auch unter Einsatz von elektronischen Agenten, ermöglichen.
SYPAM als Wissensmodell und SYCAT als Metawissensstruktur bieten aufgrund der Visualisierung von Zusammenhängen eine ontologische Basis zur gezielten Wissenssuche. Ontologien stellen ein Wissensmodell über einen bestimmten Themenkomplex (Domaine) dar. Dieses Modell legt gemeinsam verwendete Begrifflichkeiten, deren Beziehung untereinander und Regeln über diese Bezie-hungen fest. Das Themennetz – hier also das organisationale Wissen – entsteht durch die Verbindung der einzelnen Themenknoten mit übergeordneten Begrif-fen sowie durch die Verlinkung untereinander.

Bild 2: Systematische Wissensstrukturierung zum Themennetz „Or-ganisationale Wissensbasis“
Bild 2 zeigt beispielhaft das hier betrachtete Themennetz mit den Metabezugs-daten und den Themenknoten, die durch die SYPAM Felder determiniert sind. Jedem Knoten lassen sich die übergeordneten Begriffe (Schlagworte) zur Struk-turierung der Wissensbasis thematisch zuordnen. Die Suche zum Beispiel nach Dokumenten, Links, Projekten, Ansprechpartnern, Experten, Potenzialen, Me-thoden oder Managementsystemen innerhalb der integrierten Prozessgestal-tung, -optimierung, -planung, -steuerung, -durchführung, des Prozessmonito-rings und -controllings sowie der Prozessevaluierung nach unterschiedlichen Sichten, erfolgt über die Suchworte mit und / oder Verknüpfung aus dem erläu-terten standardisierten Begriffssystem und -verzeichnis nach frei auswählbaren thematischen, zeitlichen, organisatorischen und anderen Bezügen.
Zusammenfassung
Grundlage für die Entwicklung semantischer Netzwerke sind so genannte Topic Maps, ein 1999 von der ISO Organisation vereinbarter Standard (ISO/IEC 13250). Dieser Standard definiert ein Modell und eine Architektur für ein struk-turiertes Netzwerk von Hyperlinks, das mit entsprechenden Informationsobjek-ten verknüpft werden kann. Auf diese Weise wurde es möglich, große unstruk-turierte Dokumentenmengen mit Hilfe einer Wissensstruktur, die aus so ge-nannten Knoten (Sachthemen) und Kanten (Beziehungen) besteht, wissensmä-ßig aufzubereiten. Durch das Austauschformat SGML/XML können Texte durch entsprechende Merkmale (Verschlagwortung) semantisch qualifiziert werden, sodass sie kontextbezogen ausgewertet werden können. Mit diesem Ansatz sind die einfachen Datenmodelle der 90er Jahre durch die Verknüpfung von Beziehungen, Bedeutungen und Begriffe so erweitert worden, dass eine Struk-turierung von Kontextwissen möglich wurde. Das hier vorgestellte Vorgehen zur Wissenssammlung und -strukturierung setzt für die Topic Maps Weiterent-wicklung die beschriebenen sycat/SYPAM Metawissensnetzstruktur und weitere Beschreibungsmodelle ein. Auf diese Weise wird es möglich, kontextbezogen verschiedene Informations- und Wissensarten aus unterschiedlichen Informati-onsquellen zu identifizieren, zu strukturieren, zu klassifizieren, zu verknüpfen, zu verwalten und wieder auffinden zu lassen und dieses Wissen dann aufberei-tet für individuelle und kollektive Lernprozesse bei der Aufgabendurchführung zur Verfügung zu stellen.




